30.04.2020
30.04.2020 
A lot of us have experienced a hard disk or an SSD failure. Some of us have even tried to find out more about the reliability of hard drives and their hidden prediction function that's part of a technology called SMART. One might argue that SMART is not as reliable as it does not predict failure in all cases. This fact is partly true, but the actual inner workings of this self-monitoring system are not so simple, so let's examine how SMART works. We're also going to show you how to check the HDD SMART status, as well as the solid-state drive SMART status:
What is SMART (HDD & SSD)?
SMART is a system that monitors the internal information of your drive. Its clever name is actually an acronym for Self-Monitoring, Analysis, and Reporting Technology. SMART, also written as S.M.A.R.T., is a technology found inside HDDs and SSDs. It is independent of your operating system, BIOS, or other software.
What does SMART do for HDDs and SSDs?
SMART was invented because computers needed something that could monitor the health state of their hard drives. That means, plainly speaking, that SMART should supposedly be able to tell you if your hard drive or solid-state drive is about to stop working!
How does SMART do that? You might be tempted to think that SMART can magically guess if your drive is healthy. 🙂 What it does is an entirely different story, though. SMART keeps track of a series of variables whose number and type vary from drive to drive, which are indicators of its reliability. If you want to get an in-depth idea of all the SMART attributes, as there are about 50 of them (raw read error rate, spin-up time, reported uncorrectable errors, power-on time, load cycle count, etc.), visit this webpage.
However, know that, apart from some singular attempts (Google, Backblaze), most of the S.M.A.R.T. data is undocumented. The system provides a great deal of internal data. Still, there are many inconsistencies in the statistics because many of the hard drive manufacturers use different definitions and measurements. For example, some manufacturers store power on-time data as hours, while others measure it in minutes or seconds. Also, they don't explain which of the various attributes or variables are worth our attention, making us drown in data.
Before attempting to understand which SMART attributes are relevant, we first have to differentiate between the main types of SSD and HDD failures: predictable and non-predictable.
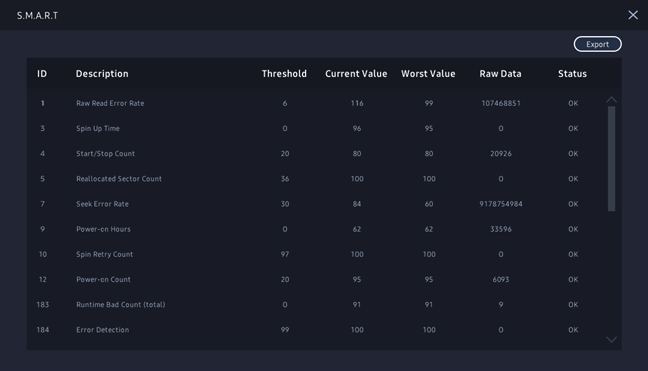
Predictable failures include the breakdowns that appear in time and are caused by faulty disk mechanics or damages of the disk's surface in the case of hard-disks. For solid-state drives, predictable failures can include normal wear over time or a high number of erasing attempts that have failed. Problems get worse over time, and the drive eventually fails.
Non-predictable failures are caused by sudden events, of which we can mention, for example, sudden power surges or unexpected damage to circuitry inside the hard disk or solid-state drive. What is important to understand is that S.M.A.R.T. can only help you detect predictable failures.
Now that you have a basic understanding of what SMART is and does, let's see how to check the SMART status of your drives from Windows and then also how to read and interpret the SMART details:
How to check SSD and HDD SMART status
On Windows computers and devices, the easiest way to read SMART data from a hard disk or from an SSD is by using specialized apps. There are quite a few out there, but many of them are either poorly developed or cost money. Out of all the apps that can read SMART data, the best and the one that we're recommending that you use is CrystalDiskInfo. It is free, able to read SMART attributes, and it's also one of the few such apps that can get SMART data both from IDE(PATA), SATA, and NVMe drives, as well as from portable drives that are using eSATA, USB, or IEEE 1394.
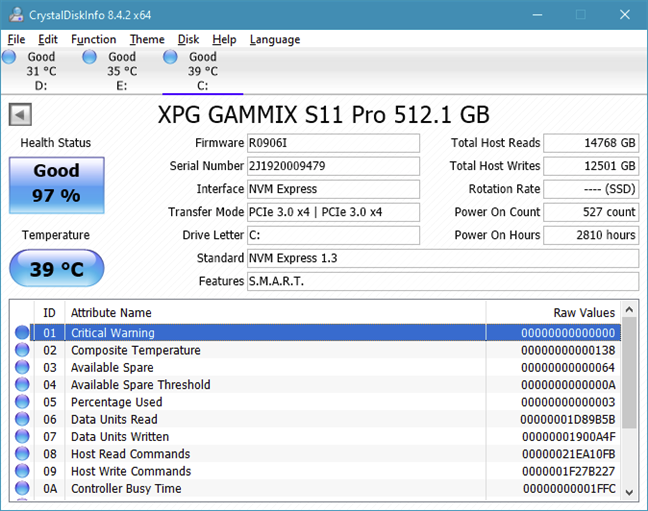
Another excellent method of checking the SMART status and details of an HDD or SSD is to use the apps provided by its manufacturer. For example, most solid-state drives are accompanied by support apps that let you check information about them, check their health, run diagnostics, and so on. These apps usually include options for checking SMART status.
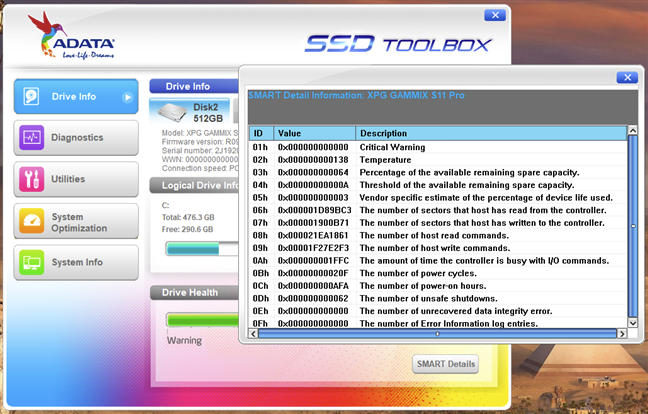
A third way of checking the SMART status of your hard disk drive or SSD is offered by Windows 10. It doesn't show details, but can tell you whether the SMART status of your drives is OK or not. To check SMART, open Command Prompt and run this command: wmic diskdrive get model, status. The command outputs the list of drives connected to your PC and shows the SMART status for each of them.
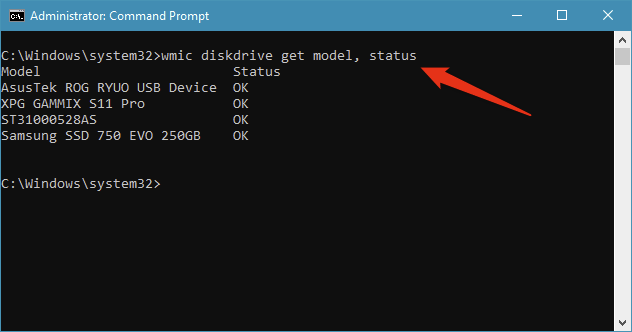
This last method to check the SMART status is probably the quickest way in Windows 10 to check whether your drives are failing.
How to run an SSD or HDD SMART test
If you're not satisfied with just reading the SMART status of your drives, you can also run an SSD or HDD SMART test. That is easier said than done because you need a specialized app for this purpose. Accordingly, we considered that this is a subject worthy of a separate article, which you can access via this link: Test your HDD or SSD and check its health status.
How to read SMART values and attributes
The health status of the hard disk is continuously tested and monitored with multiple sensors. The values are measured by the use of typical algorithms, and then the corresponding attributes are tweaked according to the results.
In any SMART monitoring program, you should see attributes that contain at least some of these fields:
- Identifier: the definition of the attribute. It usually has a standard meaning, and it is marked with a number between 1 and 250 (for example, 9 is Power-on Count). Still, all disk monitoring and testing tools provide the name and a textual description of the attribute.
- Threshold: the minimum value for the attribute. If this value is reached, then your drive is about to fail.
- Value: current value of the attribute. The algorithm calculates this number based upon the raw data. A new hard drive should have a high number, the theoretical maximum (100, 200, or 253 depending on the manufacturer), that decreases during its lifetime.
- Worst: the smallest value of the attribute ever recorded.
- Data: raw measured values provided by a sensor or a counter. This is the data used by the algorithm designed by the manufacturer of the HDD or SSD. Its contents depend on the attribute and the maker of the drive. Regular users should skip this one.
- Flags: the purpose of the attribute. This is usually set by the manufacturer and therefore varies from drive to drive. Each of the attributes is either critical and can predict an imminent failure (for example, ID 5 reallocated sectors count), or statistical with no direct effect on status (for example, ID 174 unexpected power loss count).
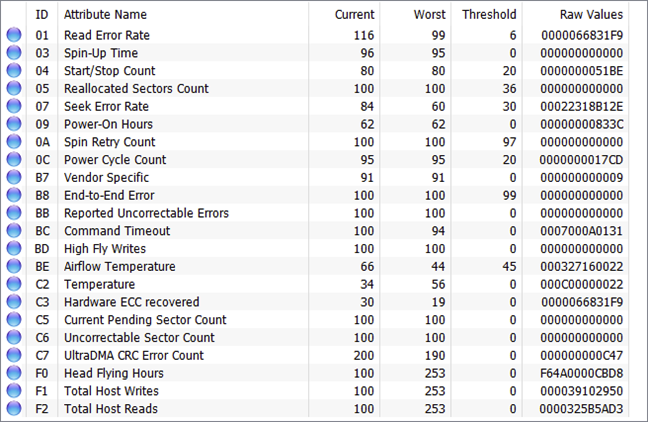
When trying to understand the status of any S.M.A.R.T. attribute, check the values of these three fields: value, threshold, and flags. Also, remember that, usually, smaller values are an indication of a decrease in reliability.
How to use SMART to predict the failure of an HDD or SSD (essential values to check)
Not all S.M.A.R.T. attributes are critical for failure prediction. The two above mentioned studies on hard drive failure rates and other sources agree that an important help in identifying failing drives are:
-
Reallocated sector counts. Reallocation happens when the drive's logic remaps a damaged sector, as a result of recurring soft or hard errors, to a new physical sector from its spare ones. This attribute reflects the number of times a remapping has happened. If its value increases, it's an indication of HDD or SSD wear.
-
Current Pending Sector Count. This counts the "unstable" sectors, meaning the damaged ones with read errors that are waiting for a remapping, a kind of "probation" system. S.M.A.R.T. algorithms have mixed understandings about this particular attribute, as it is sometimes unconvincing. Still, it can provide an earlier warning of possible problems.
-
Reported Uncorrectable Errors. It is the count of errors that are impossible to recover, and it is useful because it seems to have the same meaning for all manufacturers.
-
Erase Fail Count. This one is an excellent indicator of the premature death of a solid-state drive. It counts the number of failed data deletion attempts, and a value that increases tells you that the flash memory inside the SSD is close to its end-of-life.
-
Wear Leveling Count. This is also especially useful for SSDs. Manufacturers set the expected lifetime of an SSD in its SMART data. The Wear Leveling Count is an estimation of the health of your drive. It is calculated using an algorithm that takes into account the predefined expected lifetime and the number of cycles (write, erase, etc.) that each memory flash block can perform before reaching its end-of-life.
-
Disk temperature is a highly debated parameter. Still, it is considered that values above 60°C can reduce the lifespan of an HDD or SSD and increase the probability of damage. We recommend using a fan to decrease the temperature of your drives and hopefully prolong their life.
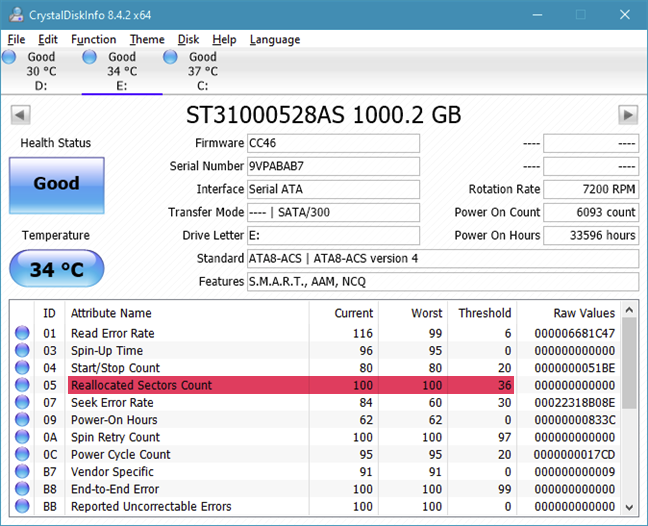
The above mentioned S.M.A.R.T. attributes are relatively easy to interpret. If you notice an increase in their values, it is possible that your drive is failing, so you'd better start backing up. However, although these are useful indicators of drive reliability, do not forget that they are not foolproof.
Historical note about SMART
SMART was developed beginning with the year 1992, although you know now that it is included by all modern solid-state drives and hard disk drives. Its history covers an array of names like Predictive Failure Analysis or IntelliSafe and input from all the major hard disk manufacturers: IBM, Seagate, Quantum, Western Digital. Finally, its documentation was featured for the first time in 2004 within the Parallel ATA standard and received regular revisions afterward. The latest one was issued in 2011.
Is there anything else you would like to know about SSD and HDD SMART?
This was our short study on the inner workings of S.M.A.R.T and its abilities to monitor, test, and predict hard disk failures. The main point of view you should remember is that this self-monitoring system can help you review the health status of your HDD. If you want to use this S.M.A.R.T data to see if your own drive has problems, read the articles we recommended in this tutorial. Also, for questions, use the comments form below, and let's discuss.